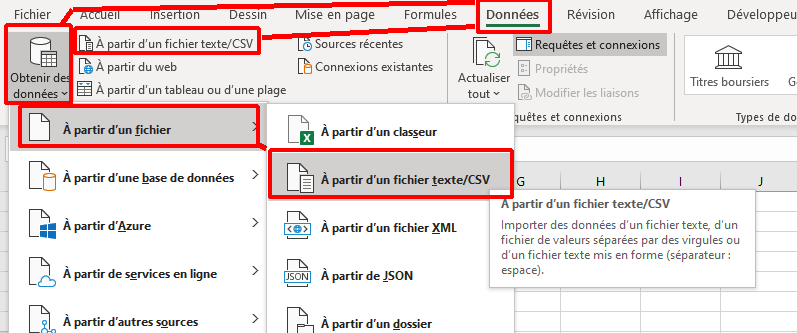
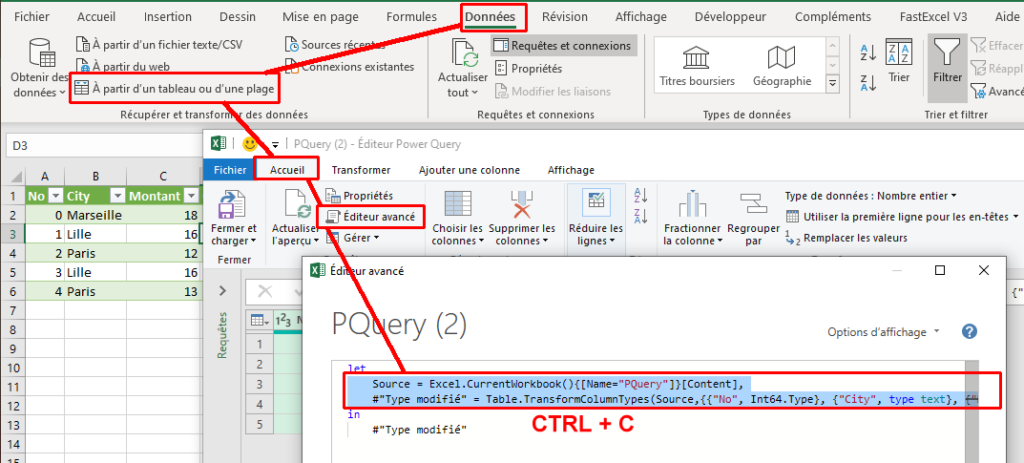
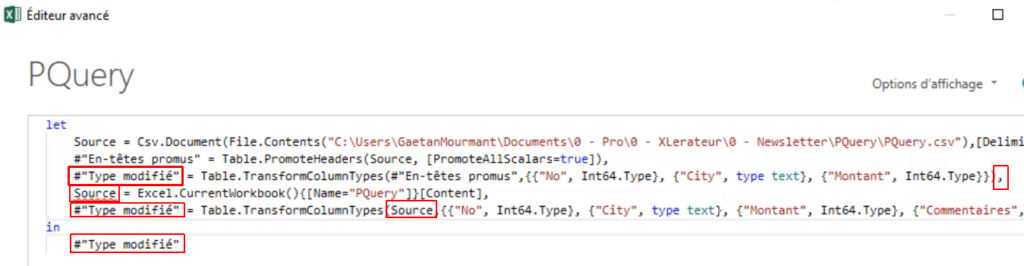
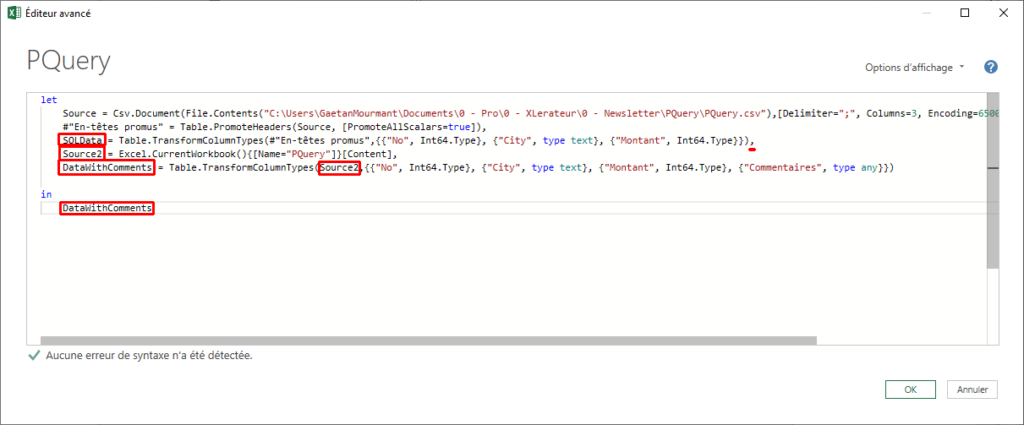
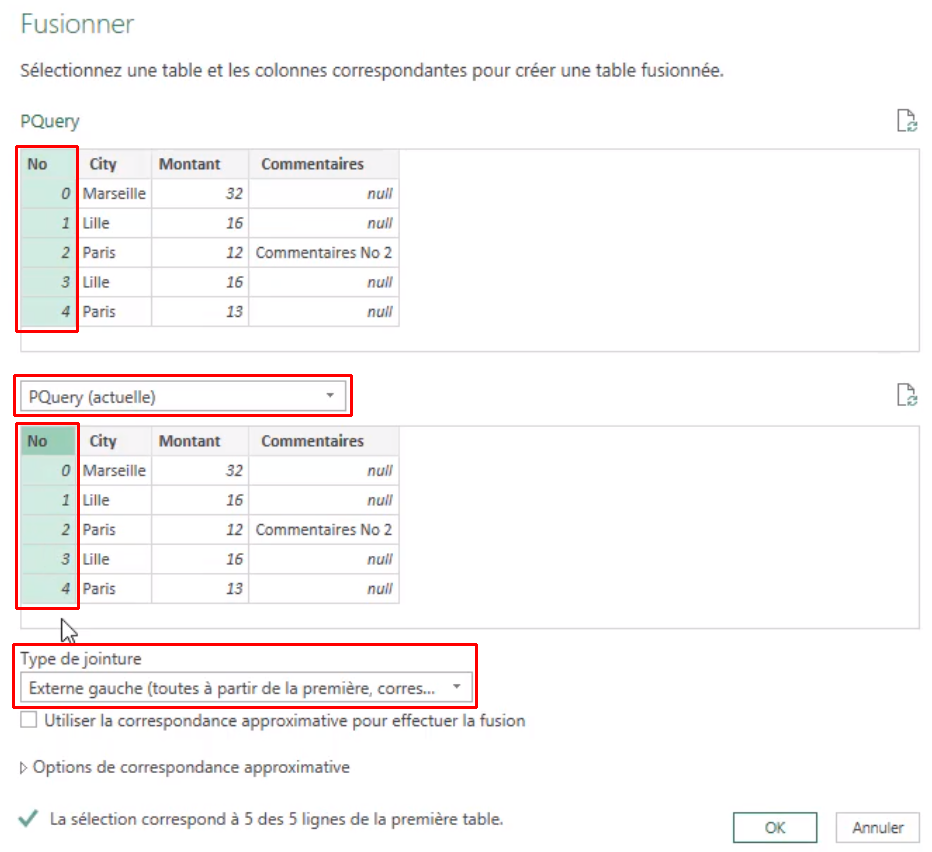
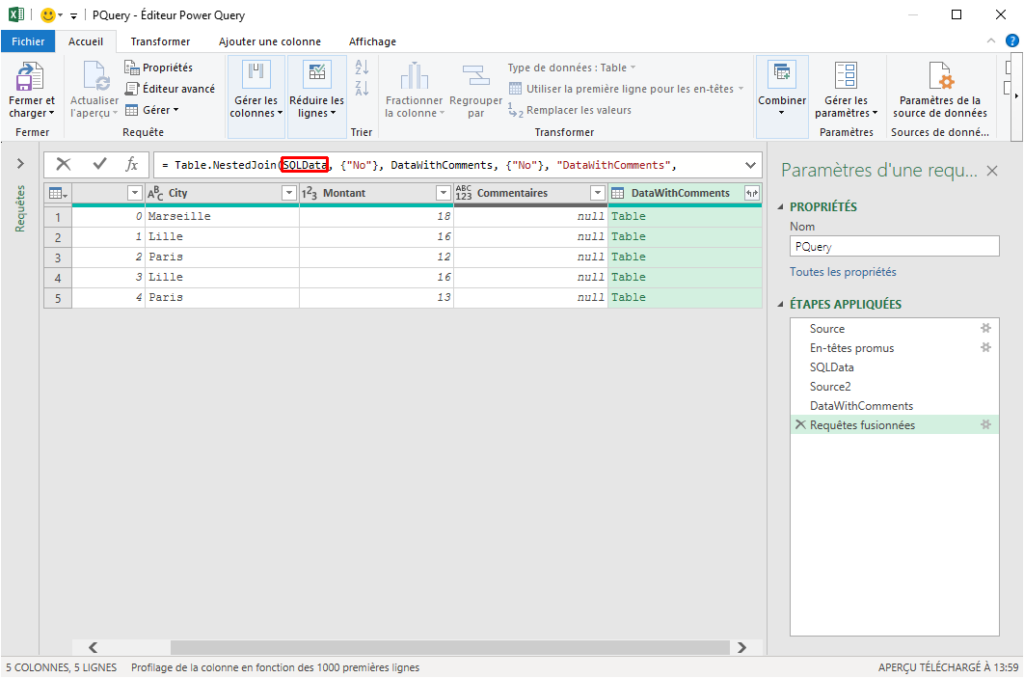
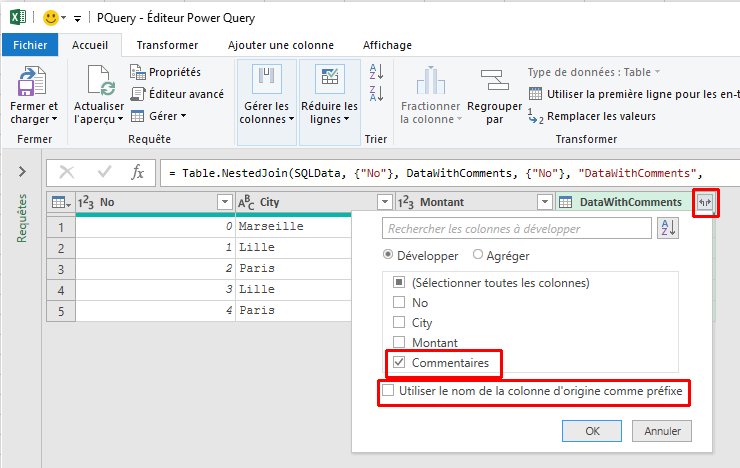
Vous connaissez certainement la fonction SIERREUR. Elle permet de remplacer la combinaison = SI(ESTERREUR(...)).
Voici une autre fonction qui permet d'identifier l'erreur #N/A, au lieu d'utiliser =SI(ESTNA(...)).
Elle s'utilise de la même manière que SIERREUR :
=SI.NON.DISP(valeur, valeur_si_na)
Quand utiliser l'une par rapport à l'autre?
Evidemment, cela dépend de la situation.
- Si vous ne voulez capturer que l'erreur NA, le cas le plus courant étant une RECHERCHEV ou un INDEX/EQUIV, alors, utilisez SI.NON.DISP
- Si vous voulez capturer toutes les erreurs, alors on utilise SIERREUR.
Par exemple, supposons que vous vouliez retouner la valeur du CA pour la ville sélectionnée, en gérant l'erreur.

Si la valeur cherchée existe (Lille), mais qu'elle renvoit une valeur d'erreur (ici #DIV/0), la fonction SI.NON.DISP va retourner la valeur d'erreur, ce qui est une bonne chose, car l'information retournée est plus précise. La fonction SIERREUR retourne le message d'erreur indiqué dans la formule.
Dans le cas de Parris (avec deux "r"), les deux fonctions vont retourner le message d'erreur indiqué dans la formule.
Question subsidiaire, mais pourquoi n'ont ils par utilisé la fonction SINA !!!
PS : pour en savoir plus sur la combinaison INDEX/EQUIV, regardez cette série de vidéo :